
Neste artigo, analisamos o SOPHGO SC7 HP75 — um acelerador tensorial que, à primeira vista, pode parecer mais uma alternativa entre muitas no mercado de aceleradores para IA.
À primeira impressão, ele se encaixa no perfil de um produto ambicioso, ainda em fase de consolidação em termos de ecossistema, documentação e suporte aos principais frameworks. Mas será que essa percepção corresponde à realidade? É isso que vamos verificar a seguir.
O papel dos TPUs e dos decodificadores de vídeo de alto desempenho em soluções de IA
Processadores tensoriais (TPU) e processadores neurais (NPU) representam o próximo estágio de evolução dos dispositivos de computação especializados para tarefas de inteligência artificial. Esses processadores são projetados levando em conta os requisitos específicos impostos pelos algoritmos de aprendizado de máquina e redes neurais profundas.
Os TPUs são otimizados para trabalhar com tensores — matrizes multidimensionais de dados que formam a base da maioria dos modelos modernos de deep learning. A principal vantagem dos TPUs está no uso de unidades de multiplicação matricial (MXU), que executam operações de multiplicação de matrizes e vetores com altíssima velocidade.
Isso os torna uma solução eficiente tanto para treinamento quanto para inferência de modelos grandes, como modelos de linguagem ou sistemas de reconhecimento de imagens, onde é necessário um processamento intensivo de cálculos matriciais.
Por outro lado, os NPUs representam uma solução mais flexível, combinando as vantagens dos TPUs com recursos adicionais para trabalhar com diferentes tipos de redes neurais. Os NPUs geralmente incluem blocos especializados para executar operações de convolução, ativação e pooling — todos componentes importantes das redes neurais convolucionais (CNN) usadas em tarefas de visão computacional.
Além disso, os NPUs são otimizados para trabalhar com diferentes níveis de precisão de dados, permitindo encontrar um equilíbrio entre desempenho e eficiência energética.
A principal diferença entre TPUs/NPUs e GPUs está na capacidade de executar com mais eficiência tarefas especializadas de redes neurais. Enquanto as GPUs continuam sendo dispositivos de computação de uso geral, capazes de lidar com uma ampla gama de cálculos paralelos, TPUs e NPUs oferecem desempenho e eficiência energética incomparáveis em tarefas de IA altamente direcionadas.
No caso do SC7 HP75, além de ser um TPU e não uma GPU tradicional, destacam-se também seus decodificadores de vídeo, que suportam os codecs H.264 e H.265 e podem processar até 2400 quadros por segundo em resolução 1080p.
A importância disso é difícil de superestimar para quem trabalha com múltiplos fluxos de vídeo simultaneamente: desde sistemas de segurança com reconhecimento facial até análises comportamentais em “cidades inteligentes”. Apenas poder computacional, sem a capacidade de processar grandes volumes de vídeo, teria pouco sentido, pois os decodificadores se tornariam o gargalo de todo o acelerador.
Especificações do SC7 HP75
Agora vamos ao que torna o SC7 HP75 tão atraente para trabalhar com redes neurais. Ele é baseado em um processador ARM A53 de 24 núcleos com clock de 2,3 GHz, fornecendo até 169.280 DMIPS de poder computacional.
Em termos de desempenho, o SC7 HP75 atinge até 96 TOPS em INT8, 48 TFLOPS em FP16/BF16 e até 6 TFLOPS em FP32. Isso o torna adequado para tarefas intensivas de IA, incluindo treinamento e inferência de modelos grandes.
O TDP do SC7 HP75 é de modestos 75 watts, de modo que até mesmo a refrigeração passiva é suficiente — a arquitetura ARM mais uma vez mostrou sua alta eficiência energética. A placa conta com 48 GB de memória LPDDR4x com largura de banda de 205 GB/s, garantindo alta velocidade de acesso aos dados. A conexão é feita via PCIe Gen3 x16, com suporte também a PCIe Gen3 x8.

Atenção especial foi dada ao processamento de vídeo: decodificação H.264 e H.265 de até 2400 quadros por segundo em 1080p, além de suporte a resoluções 8K, 4K, 1080p, 720p e inferiores.
As capacidades de codificação incluem até 900 quadros por segundo em 1080p, com suporte a 4K e 1080p, tornando este acelerador ideal para trabalhar com grandes quantidades de fluxos de vídeo em sistemas de segurança e cidades inteligentes. A codificação de imagens JPEG pode atingir até 1200 imagens por segundo em 1080p, com resolução máxima de até 32.768 × 32.768 pixels.
É declarado suporte aos principais frameworks de IA, como TensorFlow, PyTorch, Caffe, MXNet e ONNX, bem como a sistemas operacionais baseados no kernel Linux.
Locação de serviços GPU em nuvem
Arquitetura ARM: eficiência energética e velocidade
A base do SC7 HP75 é um ARM A53 de 24 núcleos com clock de 2,3 GHz. A arquitetura ARM há muito se estabeleceu como uma solução eficiente e econômica em energia, e no caso do SC7 HP75 isso desempenha um papel fundamental.
Quanto mais rápido e eficientemente os dados podem ser processados, mais tarefas podem ser realizadas por unidade de tempo — algo especialmente importante ao trabalhar com vídeo e inferência em tempo real.
Além disso, a arquitetura ARM permite que o SC7 HP75 supere concorrentes como o Nvidia T4, especialmente em tarefas que exigem resposta rápida e baixa latência na análise de fluxos de vídeo e reconhecimento de objetos.
Comparação com o Nvidia T4
Quando se fala em desempenho, o SC7 HP75 claramente desafia o Nvidia T4. Em testes com modelos de deep learning como o ResNet-50, o SC7 HP75 mostra bons resultados: 7082 operações por segundo contra 6285 do T4.
Em tarefas de detecção de objetos, como o SSD-Large, o SC7 HP75 novamente fica à frente com 149 contra 142 do concorrente, além de 214 no BERT-LARGE contra 213 do T4.
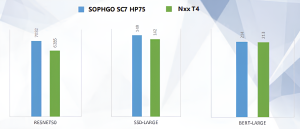
Resultados dos testes
Os testes do SOPHGO SC7 HP75 mostraram sua alta eficiência em tarefas de inferência de redes neurais. Em comparação com um servidor baseado em GPU (Nvidia A16-16) usando o modelo YOLOv5s, o acelerador TPU processou um vídeo de 30 segundos em 6,2 segundos, enquanto a GPU precisou de 7,8 segundos. A diferença na detecção de objetos foi mínima (<0,04%), confirmando a precisão e estabilidade do TPU.
Em um teste de processamento de áudio usando o Whisper Medium em dois SOPHGO SC7+ (6 TPUs), o sistema apresentou o seguinte resultado: 12 arquivos de áudio com duração de 883 segundos cada (total de 10.596 segundos) foram processados em 1326 segundos, fornecendo uma taxa de 7,99 segundos de áudio por segundo de tempo real. O tempo médio de processamento por solicitação foi de 661 segundos.
Isso prova que os TPUs da SOPHGO são capazes de lidar eficientemente com tarefas de inferência em tempo real, especialmente em cenários relacionados a processamento de streaming, visão computacional e ASR (reconhecimento automático de fala).
O principal é o software
Claro, testes e números são ótimos, mas hardware sem software é apenas um pedaço caro de metal. E é aqui que começam os verdadeiros desafios. Não importa o quão bom seja o “recheio”, se o suporte de software e a compatibilidade com frameworks populares deixam a desejar. No fim das contas, tudo se resume a como esse poder será implementado na prática, em tarefas reais, e não em testes de laboratório.
A Nvidia vem refinando o ecossistema CUDA há décadas, investindo enormes recursos no desenvolvimento de APIs, drivers, ferramentas e documentação, para que qualquer desenvolvedor possa facilmente incorporar aceleração por hardware em seu trabalho. Pegue qualquer framework popular de redes neurais — TensorFlow, PyTorch ou Caffe — e você verá que a maioria deles prioriza o suporte à NVIDIA.
A SOPHGO, entendendo a importância do suporte de software, fez todo o possível para que o SC7 HP75 fosse o mais compatível possível com os principais frameworks. Trabalha com TensorFlow ou PyTorch? Sem problemas.
Caffe ou MXNet? Também não há obstáculos. Além disso, o SophonSDK oferece ferramentas prontas para a migração rápida de modelos existentes para o SC7 HP75. E isso não é apenas marketing — é software realmente funcional que poupa muita dor de cabeça na integração de um novo hardware.
Conclusão
O SOPHGO SC7 HP75 não é apenas mais um acelerador tensorial. A empresa conseguiu criar um produto que não só possui alto poder computacional e é capaz de competir com a NVIDIA em benchmarks, como também demonstra excelente compatibilidade com frameworks populares como TensorFlow, PyTorch, Caffe e MXNet.
O suporte a essas ferramentas, juntamente com documentação detalhada e o SDK SophonSDK, torna a integração desse acelerador em infraestruturas existentes simples e conveniente.
Se você já precisa agora de uma solução pronta para trabalhar com redes neurais, a nossa plataforma ITGLOBAL.COM — AI Cloud pode atender plenamente às suas necessidades. Dentro da plataforma estão disponíveis não apenas o SC7 HP75, mas também aceleradores como o L40S e o H100, apresentados em reviews anteriores.
Para quem deseja uma solução totalmente sob medida, a ITGLOBAL.COM também pode atuar como integrador de sistemas, oferecendo suporte desde o fornecimento de equipamentos até o projeto e a manutenção de toda a infraestrutura do zero, de acordo com suas necessidades.
Perguntas Frequentes (FAQ)
O que é o SOPHGO SC7 HP75?
O SOPHGO SC7 HP75 é um acelerador tensorial especializado para IA que oferece alto desempenho para tarefas como inferência e treinamento de modelos de deep learning, além de processamento de vídeo em alta velocidade.
Quais são os principais benefícios do SC7 HP75?
O SC7 HP75 se destaca pelo seu poder computacional de até 96 TOPS em INT8, 48 TFLOPS em FP16/BF16, e até 6 TFLOPS em FP32, além de suporte para decodificação de vídeo H.264 e H.265 a 2400 quadros por segundo em 1080p.
Como o SC7 HP75 se compara com outros aceleradores, como o Nvidia T4?
O SC7 HP75 tem um desempenho superior ao Nvidia T4 em várias tarefas de deep learning e detecção de objetos, além de processar vídeos com maior eficiência e menor latência.








